
参考:https://www.jianshu.com/p/9fe4cb316c05
数据结构:
HashMap在底层数据结构上采用了数组+链表+红黑树,通过散列映射来存储键值对数据。
扩容情况:
默认的负载因子是0.75,如果数组中已经存储的元素个数大于数组长度的75%,将会引发扩容操作。
【1】创建一个长度为原来数组长度两倍的新数组。
【2】1.7采用Entry的重新hash运算,1.8采用高于运算。
put操作步骤:
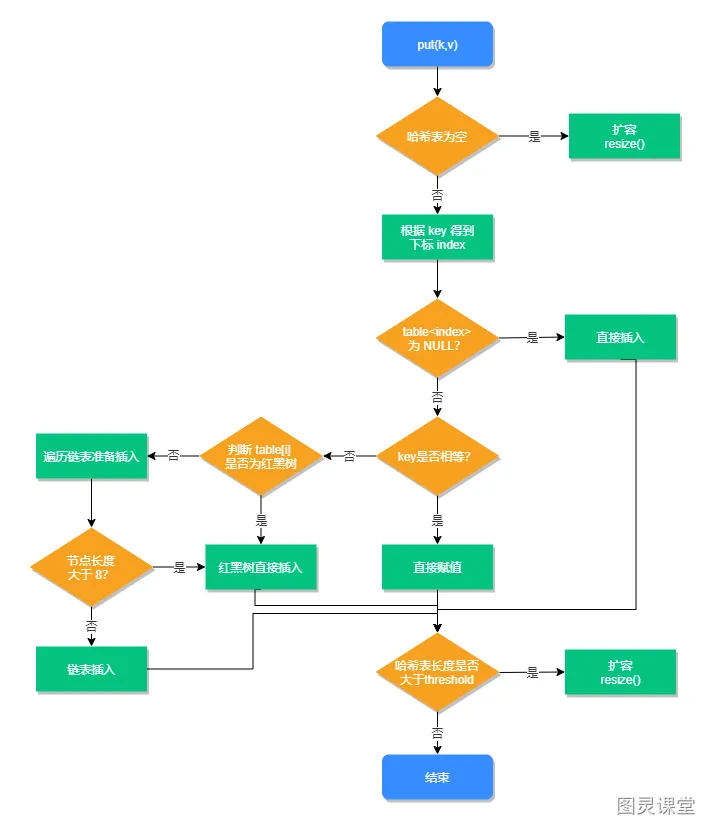

1、判断数组是否为空,为空进行初始化;
2、不为空,则计算 key的hash值,通过(n - 1) & hash计算应当存放在数组中的下标 index;
3、查看table[index] 是否存在数据,没有数据就构造一个Node节点存放在 table[index] 中;
4、存在数据,说明发生了hash冲突(存在二个节点key的hash值一样), 继续判断key是否相等,相等,用新的value替换原数据;
5、若不相等,判断当前节点类型是不是树型节点,如果是树型节点,创造树型节点插入红黑树中;
6、若不是红黑树,创建普通Node加入链表中;判断链表长度是否大于8,大于则将链表转换为红黑树;
7、插入完成之后判断当前节点数是否大于阈值,若大于,则扩容为原数组的二倍;
哈希函数:
通过hash函数(优质因子31循环累加)先拿到key的hashcode,是一个32位的值,然后让hashcode的高16位和低16位进行异或操作。该函数也称为扰动函数,做到尽可能降低hash碰撞,通过尾插法进行插入。
容量为什么始终都是2^N:
先做对数组的⻓度取模运算,得到的余数才能⽤来要存放的位置也就是对应的数组下标。这个数组下标的计算⽅法是“ (n - 1) & hash ”。(n代表数组⻓度)。方便数组的扩容和增删改时的取模。
JDK1.7与1.8的区别:
JDK1.7 HashMap:
底层是 数组和链表 结合在⼀起使⽤也就是链表散列。如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。扩容翻转时顺序不一致使用头插法会产生死循环,导致cpu100%
JDK1.8 HashMap:
底层数据结构上采用了数组+链表+红黑树;当链表⻓度⼤于阈值(默认为 8-泊松分布),数组的⻓度大于 64时,链表将转化为红⿊树,以减少搜索时间。(解决了tomcat臭名昭著的url参数dos攻击问题)


