
●Consumer API:允许应用程序订阅一个或多个主题并处理为其生成的记录流。
●Streams API:允许应用程序充当流处理器,将输入流转换为输出流。

消息Message
Kafka的数据单元称为消息。可以把消息看成是数据库里的一个“数据行”或一条“记录”。
批次
为了提高效率,消息被分批写入Kafka。提高吞吐量却加大了响应时间。
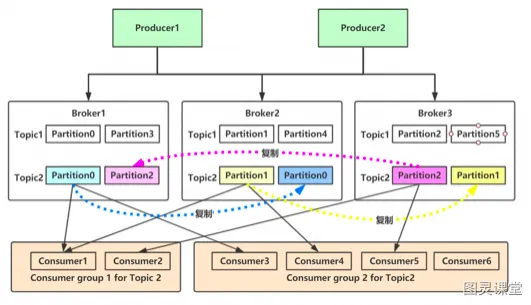
主题Topic
通过主题进行分类,类似数据库中的表。
分区Partition
Topic可以被分成若干分区分布于kafka集群中,方便扩容
单个分区内是有序的,partition设置为一才能保证全局有序
副本Replicas
每个主题被分为若干个分区,每个分区有多个副本。
生产者Producer
生产者在默认情况下把消息均衡地分布到主题的所有分区上:
●直接指定消息的分区
●根据消息的key散列取模得出分区
●轮询指定分区。
消费者Comsumer
消费者通过偏移量来区分已经读过的消息,从而消费消息。把每个分区最后读取的消息偏移量保存在Zookeeper 或Kafka上,如果消费者关闭或重启,它的读取状态不会丢失。
消费组ComsumerGroup
消费组保证每个分区只能被一个消费者使用,避免重复消费。如果群组内一个消费者失效,消费组里的其他消费者可以接管失效消费者的工作再平衡,重新分区。
节点Broker
连接生产者和消费者,单个broker可以轻松处理数千个分区以及每秒百万级的消息量。
●broker接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。
●broker为消费者提供服务,响应读取分区的请求,返回已经提交到磁盘上的消息。
集群
每隔分区都有一个首领,当分区被分配给多个broker时,会通过首领进行分区复制。
生产者Offset
消息写入的时候,每一个分区都有一个offset,即每个分区的最新最大的offset。
消费者Offset
不同消费组中的消费者可以针对一个分区存储不同的Offset,互不影响。
LogSegment
●一个分区由多个LogSegment组成,
●一个LogSegment由.log .index .timeindex组成
●.log追加是顺序写入的,文件名是以文件中第一条message的offset来命名的
●.Index进行日志删除的时候和数据查找的时候可以快速定位。
●.timeStamp则根据时间戳查找对应的偏移量。


