
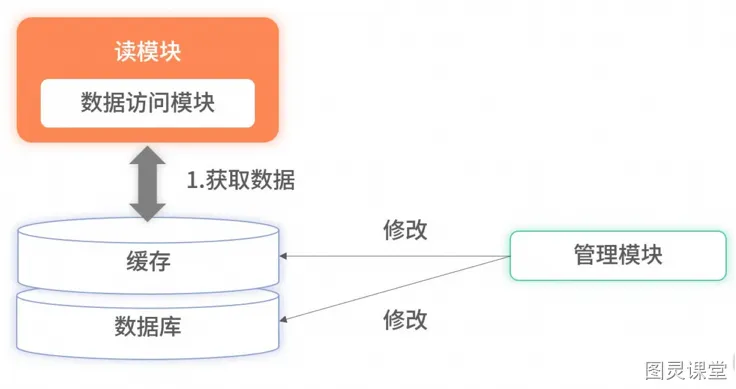

所有数据都存储在缓存里,读服务在查询时不会再降级到数据库里,所有的请求都完全依赖缓存。此时,因降级到数据库导致的毛刺问题就解决了。但全量缓存并没有解决更新时的分布式事务问题,反而把问题放大了。因为全量缓存对数据更新要求更加严格,要求所有数据库已有数据和实时更新的数据必须完全同步至缓存,不能有遗漏。对于此问题,一种有效的方案是采用订阅数据库的 Binlog 实现数据同步。
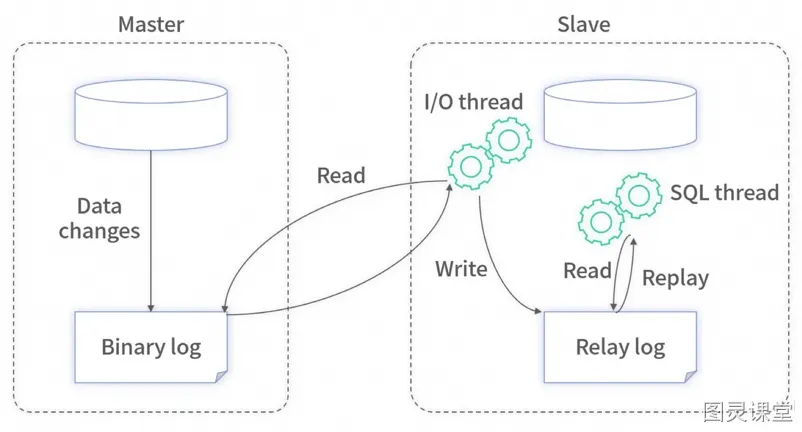

现在很多开源工具(如阿里的 Canal等)可以模拟主从复制的协议。通过模拟协议读取主数据库的 Binlog 文件,从而获取主库的所有变更。对于这些变更,它们开放了各种接口供业务服务获取数据。
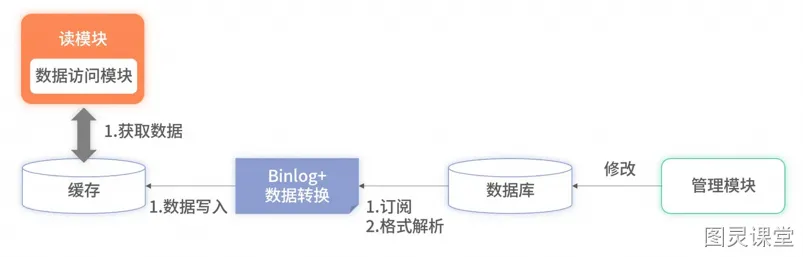

将 Binlog 的中间件挂载至目标数据库上,就可以实时获取该数据库的所有变更数据。对这些变更数据解析后,便可直接写入缓存里。优点还有:
●大幅提升了读取的速度,降低了延迟;
●Binlog 的主从复制是基于 ACK 机制, 解决了分布式事务的问题;如果同步缓存失败了,被消费的 Binlog 不会被确认,下一次会重复消费,数据最终会写入缓存中;
缺点不可避免:1、增加复杂度 2、消耗缓存资源 3、需要筛选和压缩数据 4、极端情况数据丢失;
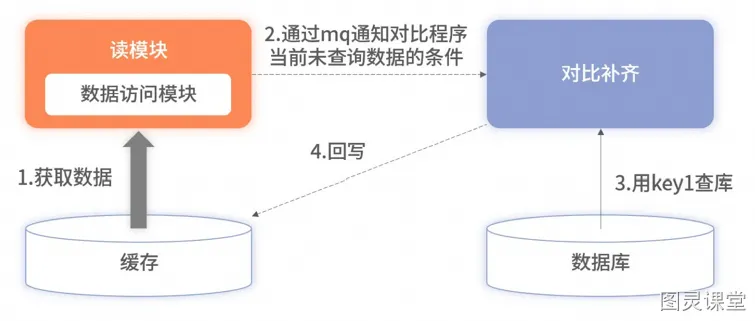

可以通过异步校准方案进行补齐,但是会损耗数据库性能。但是此方案会隐藏中间件使用错误的细节,线上环境前期更重要的是记录日志排查再做后续优化,不能本末倒置。


